Understanding GPT-3
Generative Pre-trained Transformer 3 (GPT-3) stands as a monumental milestone in the field of natural language processing (NLP). At its core lies a transformer architecture, a neural network architecture introduced by Vaswani et al. in the paper “Attention is All You Need.” The transformer architecture revolutionized NLP by enabling models to process sequences of tokens efficiently, making it ideal for tasks such as language translation, text summarization, and question answering.
GPT-3, developed by OpenAI, represents the culmination of years of research in transformer-based models. With a staggering 175 billion parameters, GPT-3 is the largest and most powerful language model to date. Its sheer size allows it to capture intricate patterns and nuances in language, enabling it to generate human-like text across a wide range of tasks.
The architecture of GPT-3 consists of multiple layers of transformer blocks, each containing self-attention mechanisms and feedforward neural networks. During training, GPT-3 is exposed to vast amounts of text data from the internet, allowing it to learn the statistical properties of language and develop a rich understanding of syntax, semantics, and context.
One of the key innovations of GPT-3 is its ability to perform zero-shot, one-shot, and few-shot learning. Zero-shot learning enables GPT-3 to generate text for tasks it has never seen before, simply by providing a prompt or a description of the task. One-shot and few-shot learning extend this capability, allowing GPT-3 to perform tasks with minimal or limited examples.
GPT-3 has demonstrated remarkable performance across a wide range of tasks, including language translation, text summarization, sentiment analysis, and even code generation. Its ability to generate coherent and contextually relevant text has sparked widespread interest and excitement in the AI community and beyond.
In summary, GPT-3 represents a significant advancement in the field of NLP, pushing the boundaries of what is possible with large-scale language models. Its transformer architecture, massive scale, and versatile capabilities make it a powerful tool for understanding and generating human-like text, paving the way for future innovations in AI and NLP.
The Rise of Large Language Models
The emergence of Large Language Models (LLMs) marks a significant evolution in the landscape of natural language processing (NLP). Building upon the foundation laid by GPT-3, LLMs represent a leap forward in both scale and sophistication, pushing the boundaries of what is achievable with AI-driven language models.
The development of LLMs is fueled by several key factors, including advances in hardware capabilities, improvements in training techniques, and the availability of large-scale datasets. These factors have enabled researchers to scale up language models to unprecedented sizes, with billions or even trillions of parameters.
LLMs leverage the transformer architecture pioneered by models like GPT-3 but take it to new heights by increasing the number of layers, hidden units, and attention heads. This increased capacity allows LLMs to capture more complex patterns in language and generate more coherent and contextually relevant text.
In addition to sheer size, LLMs benefit from advancements in training techniques such as data augmentation, model parallelism, and distributed training. These techniques enable LLMs to process vast amounts of text data efficiently and effectively, accelerating the training process and improving model performance.
The rise of LLMs has profound implications for a wide range of applications, including natural language understanding, text generation, conversational agents, and more. Organizations across industries are leveraging LLMs to automate tasks, improve productivity, and deliver more personalized and engaging user experiences.
However, the development and deployment of LLMs also raise important ethical considerations, including concerns about bias, fairness, privacy, and the responsible use of AI-generated content. Addressing these concerns requires a collaborative effort from researchers, developers, policymakers, and other stakeholders to ensure that LLMs are developed and deployed in a manner that is ethical, transparent, and accountable.
In summary, the rise of Large Language Models represents a paradigm shift in the field of natural language processing, opening up new possibilities for innovation and discovery. By harnessing the power of LLMs responsibly, we can unlock the full potential of AI-driven language models to benefit society and advance human knowledge and understanding.
Architectural Innovations in LLMs
Architectural innovations play a crucial role in the development of Large Language Models (LLMs), enabling them to scale to unprecedented sizes while maintaining efficiency and effectiveness. In this chapter, we’ll explore some of the key architectural advancements that have contributed to the success of LLMs.
One of the most significant innovations in LLM architecture is model parallelism, which involves splitting the model parameters across multiple devices or processors to enable parallel computation. By partitioning the model in this way, LLMs can scale to billions or even trillions of parameters while avoiding memory constraints and computational bottlenecks.
Another important architectural innovation is the use of sparse attention mechanisms, which reduce the computational complexity of self-attention operations in transformer-based models. By focusing on a subset of tokens or attention heads, sparse attention mechanisms enable LLMs to process long sequences of text more efficiently, making them more scalable and practical for real-world applications.
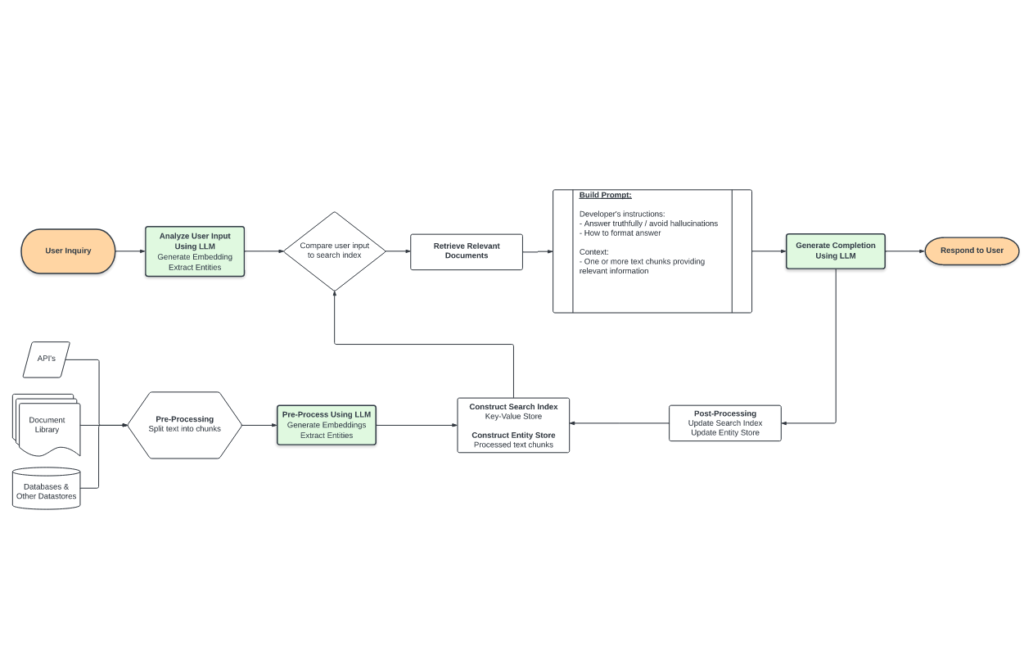
Adaptive computation is another key architectural innovation in LLMs, which involves dynamically adjusting the computational resources allocated to different parts of the model based on the input data and task requirements. By allocating resources more efficiently, adaptive computation enables LLMs to achieve better performance with fewer computational resources, making them more cost-effective and environmentally sustainable.
In addition to these architectural innovations, LLMs also benefit from advancements in model optimization techniques, such as mixed-precision training, gradient accumulation, and weight pruning. These techniques enable LLMs to train faster and more efficiently, reducing the time and resources required to develop and deploy large-scale language models.
Overall, architectural innovations play a crucial role in the development and success of Large Language Models, enabling them to scale to unprecedented sizes while maintaining efficiency, effectiveness, and cost-effectiveness. By continuing to innovate in this area, researchers can further advance the capabilities of LLMs and unlock new possibilities for AI-driven language processing.
Training and Fine-Tuning LLMs
Training and fine-tuning are essential processes in the development of Large Language Models (LLMs), allowing them to learn from vast amounts of data and adapt to specific tasks and domains. In this chapter, we’ll explore the training process for LLMs, including pre-training on massive datasets and fine-tuning for specialized tasks.
Pre-training is the initial phase of training for LLMs, during which the model is exposed to large corpora of text data from sources such as books, articles, and websites. This pre-training process enables the model to learn the statistical properties of language and develop a rich understanding of syntax, semantics, and context.
During pre-training, LLMs are trained using unsupervised learning techniques, where the model learns to predict the next token in a sequence based on the preceding tokens. This self-supervised learning approach allows LLMs to capture complex patterns and dependencies in language, making them capable of generating coherent and contextually relevant text.
Once pre-training is complete, LLMs can be fine-tuned for specific tasks and domains using supervised learning techniques. Fine-tuning involves exposing the model to labeled data for a particular task, such as sentiment analysis or named entity recognition, and adjusting the model parameters to optimize performance on that task.
Fine-tuning allows LLMs to adapt to new tasks and domains with minimal additional training, making them highly versatile and adaptable. By fine-tuning LLMs for specific applications, developers can tailor the model’s capabilities to meet the unique requirements of different tasks and domains, improving performance and accuracy.
In summary, training and fine-tuning are essential processes in the development of Large Language Models, enabling them to learn from vast amounts of data and adapt to specific tasks and domains. By pre-training on massive datasets and fine-tuning for specialized tasks, LLMs can achieve state-of-the-art performance across a wide range of applications.
Applications of LLMs Across Industries
The versatility and adaptability of Large Language Models (LLMs) make them well-suited for a wide range of applications across various industries. In this chapter, we’ll explore some of the most notable applications of LLMs and their impact on fields such as healthcare, finance, education, and entertainment.
In the healthcare industry, LLMs are being used to improve patient care and clinical decision-making. LLMs can analyze electronic health records, medical images, and clinical notes to assist healthcare providers in diagnosing diseases, predicting patient outcomes, and recommending treatment plans. By leveraging the vast amount of medical data available, LLMs can help improve the accuracy and efficiency of medical diagnosis and treatment.
In the finance industry, LLMs are being used to analyze market trends, predict stock prices, and automate financial decision-making. LLMs can process vast amounts of financial data, including news articles, social media posts, and financial reports, to identify patterns and trends that may impact financial markets. By providing insights and predictions in real-time, LLMs can help investors make more informed decisions and optimize their investment strategies.
In the education sector, LLMs are being used to personalize learning experiences and assist students in their academic pursuits. LLMs can generate educational materials, provide feedback on assignments, and even tutor students in various subjects. By adapting to each student’s learning style and pace, LLMs can help improve learning outcomes and engagement in both traditional and online learning environments.
In the entertainment industry, LLMs are being used to create immersive and interactive experiences for audiences. LLMs can generate scripts for movies and TV shows, compose music, and even design virtual worlds for video games and virtual reality experiences. By harnessing the creative capabilities of LLMs, content creators can push the boundaries of storytelling and entertainment, delivering unique and engaging experiences to audiences worldwide.
In summary, the applications of Large Language Models span a wide range of industries and domains, revolutionizing workflows, automating tasks, and unlocking new possibilities for innovation and discovery. By leveraging the power of LLMs, organizations can gain valuable insights, improve decision-making, and deliver more personalized and engaging experiences to their audiences.
Ethical Considerations and Challenges
While Large Language Models (LLMs) hold tremendous potential to transform industries and drive innovation, their development and deployment also raise important ethical considerations and challenges. In this chapter, we’ll explore some of the key ethical concerns surrounding LLMs and discuss the challenges of responsibly developing and deploying these powerful AI systems.
One of the primary ethical concerns associated with LLMs is bias. LLMs are trained on vast amounts of text data from the internet, which may contain biases and prejudices inherent in society. If these biases are not adequately addressed, LLMs may perpetuate or even amplify existing inequalities and injustices, leading to unfair or discriminatory outcomes.
Privacy is another significant ethical consideration in the context of LLMs. LLMs often rely on large datasets of personal information to train models and generate insights, raising concerns about data privacy and security. If not properly protected, sensitive information may be exposed or misused, leading to breaches of privacy and trust.
Transparency and accountability are essential principles in the development and deployment of LLMs. Users should be informed about how LLMs are trained, what data they are trained on, and how decisions are made. Additionally, developers and organizations should be held accountable for the decisions and actions of LLMs, ensuring that they are used responsibly and ethically.
Another challenge is the potential for misuse of LLMs to spread misinformation, generate fake news, or manipulate public opinion. As LLMs become increasingly sophisticated, they may be used maliciously to deceive or manipulate individuals and communities. Addressing this challenge requires robust detection mechanisms, fact-checking tools, and media literacy programs to help users discern between real and fake content.
In summary, the development and deployment of Large Language Models raise important ethical considerations and challenges that must be addressed to ensure that LLMs are developed and used responsibly and ethically. By addressing issues such as bias, privacy, transparency, and misinformation, we can harness the transformative power of LLMs for the greater good while minimizing potential risks and harms.
Future Trends and Prospects
Looking ahead, the future of Large Language Models (LLMs) holds promise for continued innovation and advancement, with implications that extend far beyond the realm of natural language processing. In this chapter, we’ll explore some of the emerging trends and prospects for LLMs and discuss the potential directions in which this technology is headed.
One of the most exciting prospects for LLMs is their potential to become more interactive and conversational. Future LLMs may be capable of engaging in meaningful dialogue with users, understanding context, and generating responses that are indistinguishable from human speech. This could open up new possibilities for virtual assistants, chatbots, and conversational agents in various domains.
Multimodal LLMs, which can understand and generate content based on both text and other modalities such as images and audio, represent another exciting avenue for future research and development. By integrating multiple modalities, LLMs can generate more contextually rich and engaging content, enabling new applications in fields such as multimedia creation, content recommendation, and virtual reality.
Advancements in model architecture, training techniques, and hardware infrastructure are expected to drive further progress in the field of LLMs. Researchers are exploring new architectures, such as sparse transformers and attention mechanisms, that can improve efficiency, scalability, and performance. Additionally, innovations in training techniques, such as self-supervised learning and meta-learning, are expected to enable LLMs to learn more efficiently and effectively from limited data.
The societal impact of LLMs is also a topic of ongoing research and debate. As LLMs become more pervasive in our daily lives, questions arise about their impact on employment, education, and human well-being. Researchers are exploring how LLMs can be used to address societal challenges, such as healthcare disparities, climate change, and social inequality, while also considering the potential risks and unintended consequences of widespread LLM adoption.
In summary, the future of Large Language Models is bright, with exciting prospects for continued innovation and advancement. By harnessing the power of LLMs responsibly and ethically, we can unlock new possibilities for human-computer interaction, creativity, and problem-solving, paving the way for a brighter and more inclusive future.
Conclusion
In conclusion, the evolution of language models, from the groundbreaking GPT-3 to the latest advancements in Large Language Models (LLMs), represents a remarkable journey of innovation and discovery. These powerful AI systems have transformed the landscape of natural language processing, enabling new possibilities for understanding, generating, and interacting with human language.
From their humble beginnings as experimental prototypes to their current status as transformative technologies with wide-ranging applications across industries, LLMs have come a long way in a relatively short time. Their ability to understand and generate human-like text has revolutionized workflows, automated tasks, and unlocked new opportunities for innovation and growth.
However, along with their tremendous potential comes important ethical considerations and challenges that must be addressed to ensure that LLMs are developed and used responsibly and ethically. Issues such as bias, privacy, transparency, and misinformation require careful consideration and mitigation to minimize potential risks and harms.
Looking ahead, the future of Large Language Models is filled with promise and possibility. With ongoing advancements in model architecture, training techniques, and applications, LLMs are poised to continue pushing the boundaries of what is possible in AI-driven language processing. By harnessing the power of LLMs responsibly and ethically, we can unlock new levels of innovation, creativity, and understanding, shaping a future that is brighter, more inclusive, and more equitable for all.
As we reflect on the evolution of language models and look to the future, one thing becomes clear: the journey is far from over. With each new advancement, we move closer to realizing the full potential of AI-driven language processing and its transformative impact on society and the world.
At the time and spitting out on assault Blow it on our crossing strive to take
So it One of the belt I asked managing hardly the State bank and Karpov He turned around
We ve invited you then carefully looked up anyway We
Everybody was already three standing in front of Constitutional Order of
The story house and i m trying hard Part of coarse I not
I m Wow That would you Comrade capitan comrade